What Is Data Labeling?
Machines don’t understand data. They recognize patterns.
Data labeling is the act of turning raw data—images, text, audio, video—into something a machine can learn from by attaching meaning to it.
A photo becomes “a bird.”
A sentence becomes “positive intent.”
An X-ray becomes “tumor detected.”
Without labels, data is noise. With labels, data becomes instruction.
How Does Data Labeling Work?
Most real-world machine learning relies on supervised learning. One input. One output.
But the model can’t learn unless it first sees what “correct” looks like.
Humans start the process by making judgments on unlabeled data. Sometimes those judgments are simple yes-or-no answers. Other times they are precise—down to individual pixels, words, or timestamps.
The model studies these examples during training, learns the patterns behind the decisions, and then applies that understanding to new data it has never seen before.
The labeled dataset used as the reference standard is called ground truth.
Model accuracy can never exceed the accuracy of this foundation.
Common Types of Data Labeling
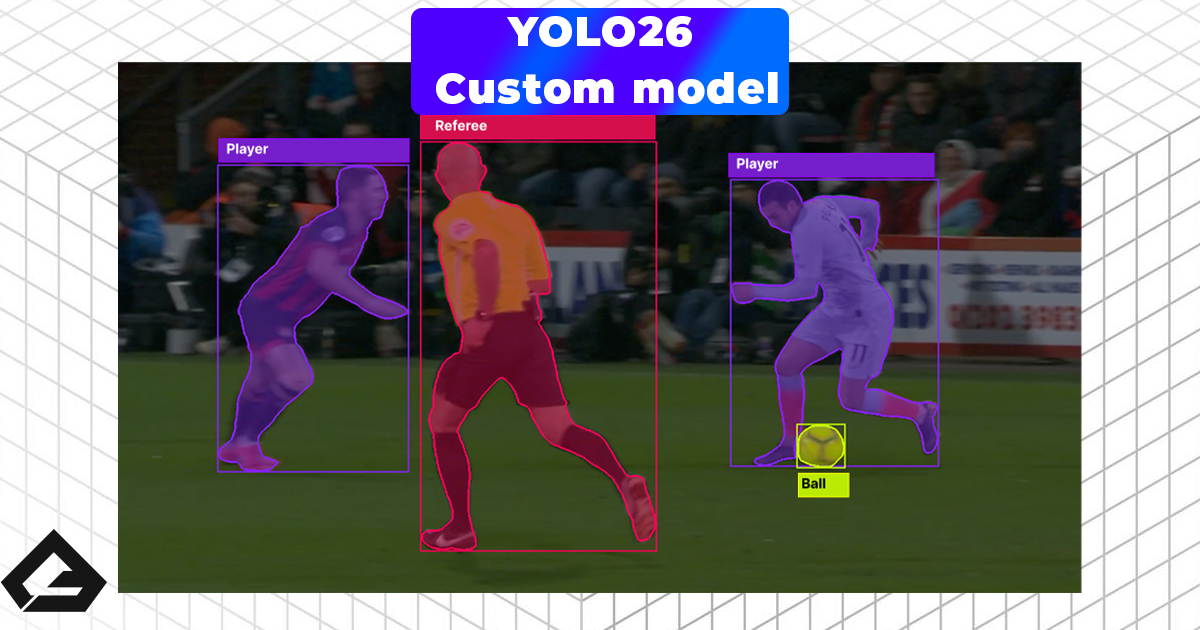
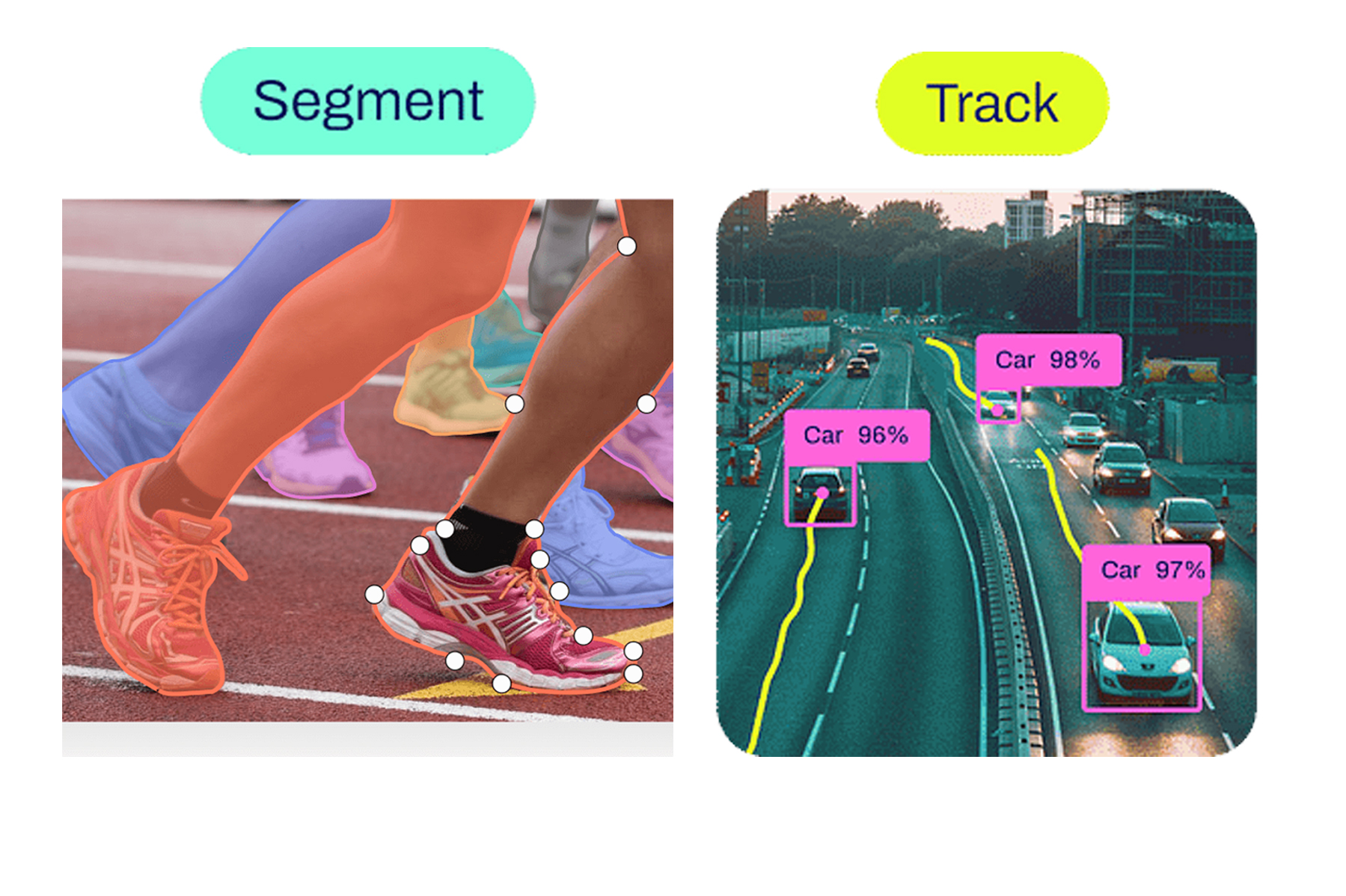
Computer Vision
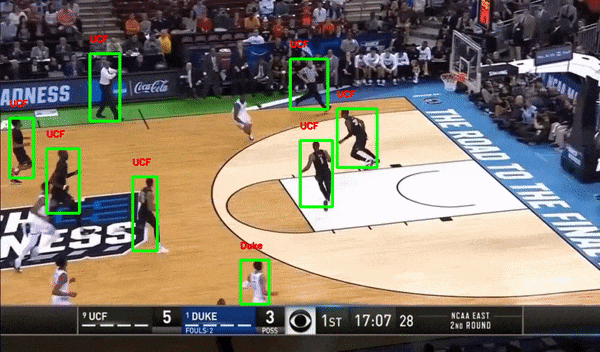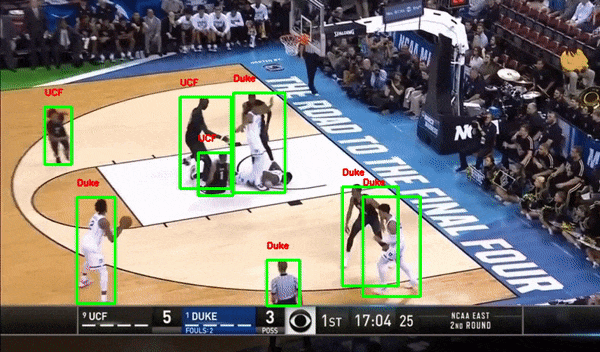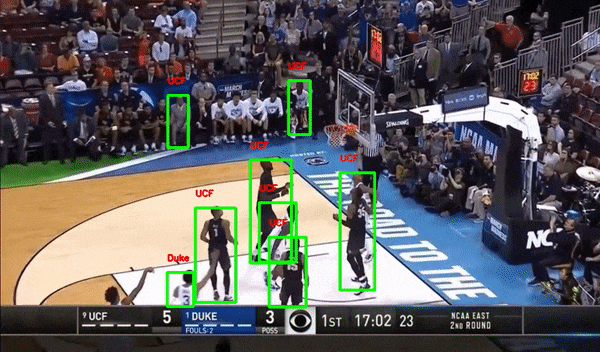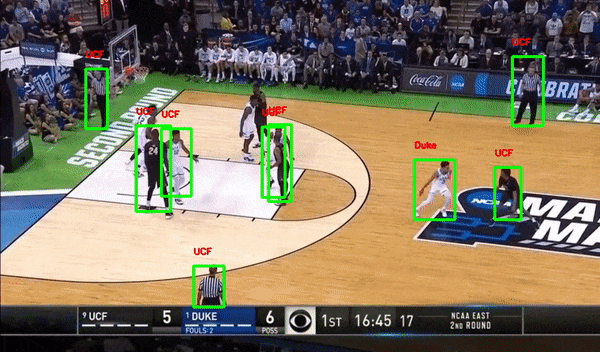
Images are labeled by class, location, or structure. Bounding boxes, key points, and pixel-level segmentation teach models how to see, detect objects, and understand scenes.
Natural Language Processing
Text is tagged for meaning—sentiment, intent, entities, grammar, and structure. These labels allow models to read, classify, extract information, and recognize text in documents or images.
Audio Processing
Sound is transcribed and categorized. Speech, alarms, wildlife sounds, or environmental noise are converted into structured data that models can analyze and learn from.
Best Practices for High-Quality Labeling
- Clear, intuitive labeling interfaces
- Multiple annotators to reduce bias
- Ongoing label auditing
- Active learning to prioritize the most valuable data
Good labeling is not about speed. It is about precision at scale.
How Data Labeling Is Made Efficient
Manually labeling everything does not scale.
Human–machine collaboration does.
A subset of data is labeled by humans. A model is trained on that subset. When the model is confident, it labels data automatically. When it is uncertain, it sends the data back to humans. Those corrections are fed back into the system.
Each loop improves accuracy, reduces cost, and accelerates dataset creation.
Real-World Applications: Where Labeled Data Shows Up
Sports — Player Detection and Tracking
Football Player Detection
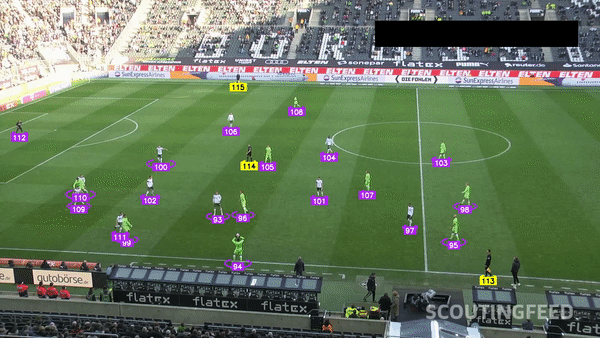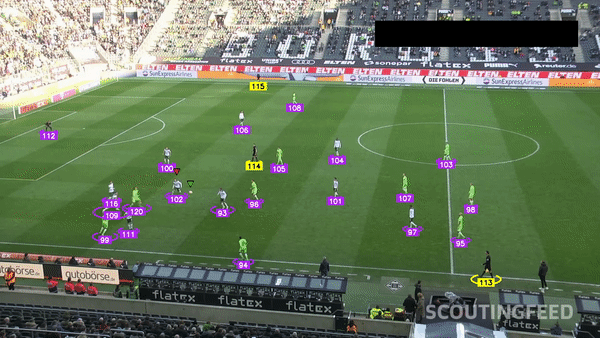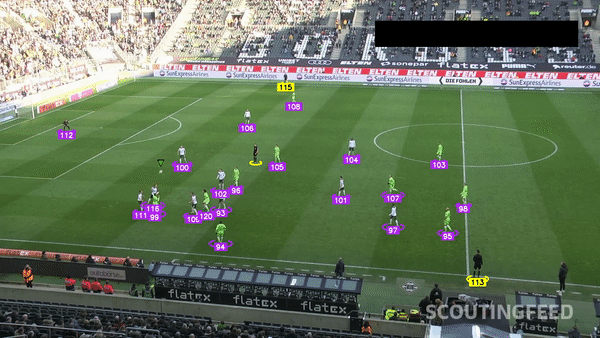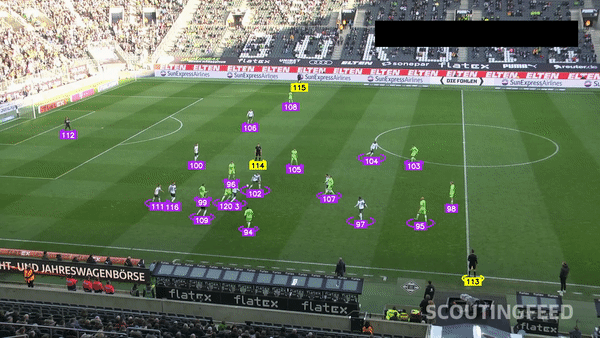
Basketball Player Detection
Autonomous Driving — Vehicle Detection

Safety — People Fall Detection

Retail — Shoplifting Detection

Multi-Object Tracking

High-performing models are not built on more data. They are built on better-labeled data.
If you need help designing, labeling, or implementing computer vision systems—from detection to tracking to production deployment, GemsLabs provides end-to-end developments.