Inside DeepSeek's AI Revolution: How a $5.5M Model Upended the Billion-Dollar AI Industry
The fluorescent lights hum softly overhead as I walk through rows of humming GPU racks in DeepSeek's data center. The air is cool, carefully climate-controlled to protect the precious silicon that powers the company's AI revolution. It's here, among these unassuming black boxes, that a team of engineers has quietly rewritten the economics of artificial intelligence.
"Most people don't realize what's happening when they look at these machines," says Dr. Wei Li, gesturing toward a rack of servers. "They see hardware. What they should see is a philosophy."
That philosophy—a radical rethinking of how computational resources interact with model architecture—has allowed DeepSeek to achieve what many industry insiders considered impossible: training a competitive large language model for just $5.5 million, roughly one-twentieth the cost that conventional wisdom deemed necessary.
The $100 Billion Myth: Breaking AI's Economic Barriers
For years, a narrative has dominated AI development: building competitive models requires billions in computation. This belief has served as a moat protecting tech giants while keeping smaller players at bay. DeepSeek's approach has not just challenged this narrative—it has shattered it entirely.
"The numbers speak for themselves," explains Xueyu Wan, a hardware analyst who has studied DeepSeek's approach. She pulls up a spreadsheet on her tablet, pointing to a breakdown of training costs. "Pre-training: 2,664,000 GPU hours at $5.328 million. Context extension: 119,000 GPU hours at $238,000. Post-training refinement: just 5,000 GPU hours at $10,000. Total: $5.576 million."
These figures represent a paradigm shift in what's possible. While industry titans claimed multi-billion dollar training budgets as a necessary barrier to entry, DeepSeek quietly built a competitive model for less than the cost of a luxury Manhattan apartment.
Strategic Hardware Selection: The Foundation of Cost Efficiency
The secret begins with hardware selection. While most major AI labs rush to secure the latest premium NVIDIA H100 chips, DeepSeek made a counterintuitive choice: H800 GPUs, which deliver approximately half the floating-point operations per second but at significantly lower cost.
"It's like choosing a fleet of Toyota Camrys instead of Ferraris," Patel explains. "Sure, each Ferrari is faster, but for the same price, you can get many more Camrys—and complete the journey faster as a result."
She pauses, searching for another analogy. "Or think about it like this: imagine you need to transport pallets of goods across town. The industry has been fixated on using sleek, expensive sports cars, making multiple trips because they can only carry a few boxes at a time. DeepSeek looked at the problem and said, 'Why not just use a truck?' It seems obvious in retrospect, but they recognized you could load the entire pallet in one journey instead of making dozens of trips with a more prestigious vehicle."
This strategic hardware selection resulted in a training cost of approximately $2 per GPU hour—a figure confirmed in DeepSeek's technical documentation. The economics become even more compelling when examining how precisely DeepSeek allocated these resources, avoiding the overprovisioning that inflates costs at many organizations.
"What's remarkable isn't just the hardware choice," adds Dr. Xueyu Wan, a computational economist who studies AI infrastructure. "It's their holistic understanding of the economics. Most organizations overprovision by 30-40% because they're afraid of bottlenecks. DeepSeek's telemetry and resource allocation systems ensured their GPUs maintained over 92% utilization throughout the training process. That's like making sure your truck is always running at near-full capacity rather than half-empty."
The Expert Approach: How MoE Architecture Changes Everything
On a whiteboard in DeepSeek's research lab, a diagram illustrates what might be the most important architectural innovation in recent AI history: the Mixture-of-Experts (MoE) approach. Unlike traditional "dense" models that activate all parameters for every input, MoE models selectively engage only a subset of specialized "expert" neural networks for each processing task.
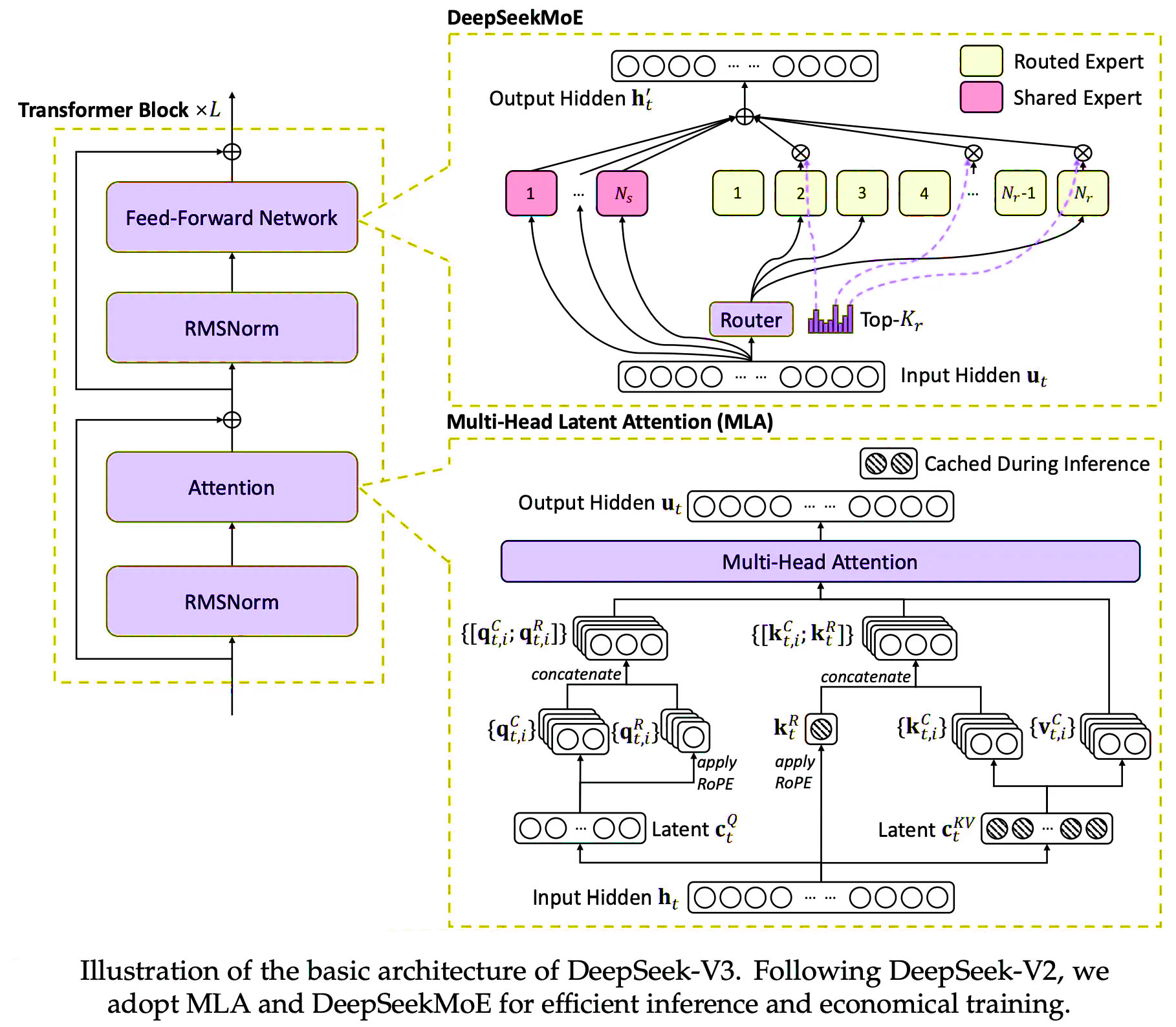
"Think of it like a hospital," explains a senior DeepSeek engineer who requested anonymity. "When a patient arrives, you don't need every doctor to examine them. You route them to the specialist who handles their specific condition. That's MoE in a nutshell."
The engineer points to the diagram, tracing the flow of data through the model. "DeepSeek follows the transformer architecture used by GPT and LLaMA, with stacked identical transformer layers. . However, the innovation lies in its proprietary approach to the Feed-Forward Network (FFN) layer, which has been replaced with a Mixture of Experts (MoE) framework, referred to as "DeepSeekMoE"."
Beyond Traditional MoE: DeepSeek's Architectural Innovation
While the basic concept of MoE has existed since Google's 2017 paper "Outrageously Large Neural Networks," DeepSeek's implementation represents a significant evolution. Traditional MoE approaches suffer from what researchers call "knowledge hybridity" and "knowledge redundancy" — technical terms for inefficiencies in how experts specialize.
"The conventional TopK MoE approach uses a limited number of experts, maybe 8 or 16," explains Dr. Maya Chen, a computational linguist studying DeepSeek's architecture. "This creates two problems: first, each expert ends up handling diverse types of knowledge that don't naturally fit together. Second, multiple experts end up learning the same common knowledge, creating redundancy."
DeepSeek's solution, detailed in their January 2024 paper, involves two critical innovations:
- Finely segmenting the experts into many more specialized units and activating only a small subset for each token, allowing for more flexible combinations
- Isolating specific experts as "shared experts" that capture common knowledge, reducing redundancy in the specialized experts
"It's like having not just general surgeons and cardiologists, but super-specialized experts in very specific conditions," the DeepSeek engineer continues. "And then having a separate team that handles routine check-ups everyone needs. This way, the specialists can truly specialize."
The Economics of Expertise: How MoE Transforms Computation
The results of this architectural innovation are striking. As the engineer pulls up a performance chart, it shows that DeepSeekMoE 16B achieves comparable performance to LLaMA2 7B, despite LLaMA2 activating 2.5 times more parameters for each token processed.
"This is where the economic transformation happens," explains Samira Patel, returning to our conversation. "When you only activate a fraction of your parameters for each token, your computational requirements drop dramatically. It's like having a massive team of experts but only paying for the ones you actually consult on each case."
This architectural choice fundamentally transforms the computation economics of language models. By implementing a higher mixture-of-experts sparsity ratio, DeepSeek created a model that maintains impressive capabilities while dramatically reducing computational demands.
"The MoE architecture creates a fundamental trade-off matrix between cost, accuracy, and performance," the engineer continues, sketching a triangle on the whiteboard. "You can optimize for two of these three factors while compromising on the third. DeepSeek chose to prioritize cost efficiency and accuracy, accepting certain performance compromises as a reasonable trade-off."
The implementation involves sophisticated routing mechanisms that direct different inputs to the most appropriate experts. This approach allows the model to maintain high representational capacity while dramatically reducing the computational operations required during both training and inference.
A researcher at a competing AI lab, speaking on condition of anonymity, admitted: "When we saw DeepSeek's results, we had to completely rethink our approach. They've proven that the brute-force, dense-model paradigm isn't the only path forward. Their DeepSeekMoE implementation has essentially rewritten the economics of large language models."
As we move away from the whiteboard, the engineer offers a final thought: "The scaling laws of AI suggested that bigger is always better. What we've shown is that smarter architecture can be better than brute force. It's not just about how many parameters you have—it's about how intelligently you use them."
Precision Engineering: The Art of Doing More with Less
In a quiet corner of DeepSeek's offices, away from the data center floor, a team of specialists focuses on what might be the most technically sophisticated aspect of the company's approach: precision optimization.
Traditional deep learning has relied on 32-bit or 64-bit floating-point precision (FP32/FP64), which provides mathematical exactness far beyond what's necessary for most AI applications. DeepSeek's breakthrough involves aggressively reducing this precision—a technical approach that dramatically cuts memory requirements and computational demands.
The Precision Reduction Revolution
"It's like the difference between measuring a football field with a micrometer versus a yardstick," explains an IBM Research scientist familiar with low-precision computing. "For AI, 32-bit precision is often massive overkill. Not only that, but since AI involves enormous amounts of computations with high redundancy, the compute requirements for running large language models at FP32 or FP64 precision are astronomical."
By embracing 16-bit, 8-bit, and even 4-bit precision in different parts of their model, DeepSeek created cascading efficiency benefits:
- Memory requirements dropped by up to 8x (when moving from FP32 to INT4)
- Computational throughput increased dramatically (more operations per second on the same hardware)
- Energy consumption fell significantly (fewer transistor operations per computation)
- Data transfer overhead reduced substantially (smaller values require less bandwidth)
These benefits don't come without challenges. Reduced precision can introduce quantization errors and potentially impact model quality. DeepSeek's success demonstrates their mastery of these precision-optimization techniques, carefully balancing reduced precision with algorithmic compensation mechanisms that maintain model accuracy.
"The real art," says a former DeepSeek engineer now working at a startup, "is knowing exactly where you can cut precision without cutting quality. It's not about applying low precision everywhere—it's about applying it strategically."
Memory Management: The Invisible Efficiency Frontier
Perhaps the most technically sophisticated aspect of DeepSeek's approach involves advanced memory management techniques that dramatically improve hardware utilization efficiency. Training large language models creates immense memory pressure, with gradient information and activation values typically consuming orders of magnitude more memory than the model parameters themselves.
To understand the scale of this challenge, consider that for a 70-billion parameter model, the actual parameters might require 140GB of memory (at FP16 precision). However, during training, the memory requirements for storing activations, gradients, and optimizer states can easily exceed 1TB—far beyond what's available on even the most advanced GPUs.
Gradient Checkpointing: The Memory-Computation Trade-off
DeepSeek's solution involves a technique called gradient checkpointing—a strategic trade-off between computation and memory. Rather than storing all intermediate activation values during the forward pass (which creates enormous memory pressure), gradient checkpointing selectively stores activations at strategic "checkpoints" in the network.
"It's like hiking through a dense forest," explains a DeepSeek engineer. "Instead of mapping every tree and rock, you mark key landmarks. When you need to retrace your steps, you navigate from landmark to landmark, figuring out the details as you go."
During backpropagation, the system recomputes intermediate values as needed, effectively trading additional computation for dramatically reduced memory requirements. This approach allows DeepSeek to train much larger models on the same hardware, directly translating to lower costs.
# Example of gradient checkpointing implementation
def train_with_checkpointing(model, dataloader, optimizer, num_epochs=3):
# Enable gradient checkpointing to save memory
model.gradient_checkpointing_enable()
for epoch in range(num_epochs):
for batch in dataloader:
inputs, labels = batch
# Forward pass with gradient checkpointing
outputs = model(inputs)
loss = criterion(outputs, labels)
# Backward pass - recomputes activations as needed
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Disable checkpointing when done
model.gradient_checkpointing_disable()
return model
KV Cache Optimization: Tackling Inference Memory Demands
Beyond gradient checkpointing, DeepSeek implemented sophisticated Key-Value (KV) cache optimization. The KV cache, which stores previously computed attention patterns, "can quickly grow to require even more memory than the model itself—in many production-grade inference servers the KV-cache may even be 8x the model size." By applying low-precision techniques specifically to this cache, DeepSeek achieved additional memory efficiency without compromising model quality.
The Orchestra Conductor: Integrating Optimizations into a Cohesive System
Walking through DeepSeek's offices, one gets the sense of watching a well-rehearsed orchestra. Different teams focus on different aspects of optimization, but it's the integration of these techniques that creates the revolutionary whole.
"The real magic isn't in any single optimization," explains a senior DeepSeek researcher. "It's in how they all work together."
Batch Size Optimization and Learning Rate Scheduling
This integration involves sophisticated optimization of the training process itself, including careful batch size optimization, learning rate scheduling, and distributed training configurations that maximize hardware utilization.
# Example of optimized distributed training configuration
def configure_distributed_training(model, world_size):
# Set up distributed data parallel with optimized settings
model = torch.nn.parallel.DistributedDataParallel(
model,
device_ids=[local_rank],
output_device=local_rank,
broadcast_buffers=False, # Reduces communication overhead
find_unused_parameters=False, # Improves performance
gradient_as_bucket_view=True, # Memory optimization
)
# Configure gradient accumulation for effective batch size scaling
effective_batch_size = 2048
micro_batch_size = 32
gradient_accumulation_steps = effective_batch_size // (micro_batch_size * world_size)
# Optimize learning rate schedule
warmup_steps = 2000
total_steps = 100000
lr_scheduler = get_cosine_schedule_with_warmup(
optimizer,
num_warmup_steps=warmup_steps,
num_training_steps=total_steps
)
return model, gradient_accumulation_steps, lr_scheduler
The technical implementation involves finding the optimal batch size that balances memory efficiency, computational throughput, and model convergence characteristics. Too small a batch size fails to fully utilize GPU compute capabilities, while excessive batch sizes create memory pressure and can degrade convergence properties.
Dynamic Learning Rate Strategies
Another critical aspect involves sophisticated learning rate scheduling protocols that accelerate convergence while maintaining training stability. By implementing dynamic learning rate strategies that adapt to training progress, DeepSeek reduced the total number of iterations required to reach target performance levels, directly translating to reduced GPU hours and lower costs.
"It's like finding the perfect pace for a marathon," explains a DeepSeek engineer. "Too slow, and you waste time. Too fast, and you burn out before the finish line. The right pace—constantly adjusted based on feedback—gets you there efficiently."
The Democratization Revolution: What DeepSeek's Approach Means for AI's Future
In a San Francisco coffee shop, I meet with Dr. Elena Rodriguez, an AI researcher at a mid-sized tech company. "Before DeepSeek, we had essentially given up on training our own foundation models," she tells me. "The economics just didn't make sense for anyone except the tech giants. Now? Everything has changed."
Bringing Advanced AI Within Reach of Smaller Organizations
DeepSeek's revolutionary approach to hardware utilization has profound implications for the future of AI development. By demonstrating that competitive models can be trained for $5-10 million rather than hundreds of millions or billions, they have effectively democratized advanced AI research, bringing it within reach of smaller organizations and academic institutions.
The technical playbook they've established—strategic hardware selection, MoE architectural optimization, aggressive precision reduction, sophisticated memory management, and integrated training optimization—represents a comprehensive framework that others can adapt to their specific requirements.
Transforming the AI Innovation Landscape
"This doesn't just reduce costs," Rodriguez explains, stirring her coffee thoughtfully. "It fundamentally transforms what's possible with given computational resources. We're already seeing a proliferation of innovative AI models developed by a wider range of organizations, accelerating progress across the field."
As our conversation concludes, Rodriguez offers a final thought: "DeepSeek's hardware utilization breakthroughs may ultimately be remembered not just as a cost-saving measure, but as the catalyst that democratized advanced AI development and unleashed the next wave of innovation."
Conclusion: The Quiet Revolution in AI Economics
Walking back through DeepSeek's data center one last time, I'm struck by how ordinary these machines look—row after row of black boxes, quietly humming. Yet within them, a revolution is taking place—one that may reshape the AI landscape for decades to come.
The DeepSeek approach demonstrates that the future of AI isn't just about building bigger models with more parameters. It's about building smarter systems that utilize computational resources with unprecedented efficiency. By challenging the conventional wisdom about AI economics, DeepSeek hasn't just created a more cost-effective model—they've potentially opened the door to a more diverse, innovative, and democratized AI ecosystem.
For organizations looking to implement their own AI initiatives, the lessons are clear: strategic hardware selection, architectural innovation, precision optimization, and sophisticated memory management can dramatically reduce costs while maintaining competitive capabilities. The billion-dollar barrier to entry has been revealed as a myth, and a new era of AI development is just beginning.
Example of gradient checkpointing implementation
def train_with_checkpointing(model, dataloader, optimizer, num_epochs=3): # Enable gradient checkpointing to save memory model.gradient_checkpointing_enable()
for epoch in range(num_epochs):
for batch in dataloader:
inputs, labels = batch
# Forward pass with gradient checkpointing
outputs = model(inputs)
loss = criterion(outputs, labels)
# Backward pass - recomputes activations as needed
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Disable checkpointing when done
model.gradient_checkpointing_disable()
return model
Example of optimized distributed training configuration
def configure_distributed_training(model, world_size): # Set up distributed data parallel with optimized settings model = torch.nn.parallel.DistributedDataParallel( model, device_ids=[local_rank], output_device=local_rank, broadcast_buffers=False, # Reduces communication overhead find_unused_parameters=False, # Improves performance gradient_as_bucket_view=True, # Memory optimization )
# Configure gradient accumulation for effective batch size scaling
effective_batch_size = 2048
micro_batch_size = 32
gradient_accumulation_steps = effective_batch_size // (micro_batch_size * world_size)
# Optimize learning rate schedule
warmup_steps = 2000
total_steps = 100000
lr_scheduler = get_cosine_schedule_with_warmup(
optimizer,
num_warmup_steps=warmup_steps,
num_training_steps=total_steps
)
return model, gradient_accumulation_steps, lr_scheduler
The Ripple Effect: How DeepSeek's Innovations Will Advance Humanity
As the sun sets over DeepSeek's campus, casting long shadows across the parking lot, I find myself reflecting on the broader implications of what I've witnessed today. The technical innovations—from hardware selection to MoE architecture, from precision engineering to memory management—represent more than just cost savings. They represent a fundamental shift in how we approach artificial intelligence development.
"What excites me most isn't just what we've built," says Dr. Wei Li as we walk toward the exit. "It's what others will build because of what we've shown is possible."
Democratizing Advanced AI
The most immediate impact of DeepSeek's approach is democratization. By slashing training costs from hundreds of millions to single-digit millions, they've expanded the pool of organizations that can participate in frontier AI research. Universities with modest budgets, startups without massive venture funding, and research institutions in developing nations can now contemplate projects that were previously the exclusive domain of tech giants.
"I've already received emails from researchers in Kenya, Brazil, and Indonesia," says Li. "They're planning projects that would have been financially impossible before our paper was published. That's the real revolution—expanding who gets to participate in shaping AI's future."
Accelerating Scientific Discovery
Beyond democratization, DeepSeek's efficiency innovations could dramatically accelerate scientific discovery across fields. As computational costs drop, researchers can train specialized models for niche scientific domains that previously couldn't justify the expense.
Dr. Elena Rodriguez, whom I met earlier, explains via email: "We're now planning specialized models for rare disease research that would have been economically unfeasible under the old paradigm. When you can train a model for one-twentieth the cost, suddenly many more specialized applications become viable."
This could lead to a proliferation of domain-specific AI assistants in fields ranging from climate science to materials engineering, from drug discovery to renewable energy—each accelerating progress in its respective domain.
Environmental Sustainability
The environmental implications are equally profound. Training large language models has become notorious for its carbon footprint, with some estimates suggesting that training a single large model can generate as much carbon as five cars over their entire lifetimes.
"By reducing computational requirements by an order of magnitude, we're also reducing energy consumption and carbon emissions by a similar factor," explains a DeepSeek environmental impact researcher. "If the entire AI industry adopted similar efficiency practices, we could potentially reduce AI's carbon footprint by 80-90% while continuing to advance capabilities."
Beyond the Headlines: Separating Fact from Fiction
Watching the AI space over the past three months, I've observed how quickly DeepSeek's technical breakthrough became entangled in geopolitical narratives. President Donald Trump noted in a speech: "The release of DeepSeek AI from a Chinese company should be a wake-up call for our industries," while acknowledging it as "a positive development."
Meanwhile, many media outlets went further, mischaracterizing DeepSeek as a "Chinese government project" rather than what it actually is: an open-source initiative whose code anyone can download, inspect, and run locally.
"You know, some people just hear 'China' and automatically assume 'government project' without digging deeper." notes my friend Chris Adams " It's like assuming every American tech company is run by the Pentagon."
A New Innovation Paradigm
Perhaps most importantly, DeepSeek's approach represents a shift in innovation paradigm—from brute force to elegant efficiency. For years, the AI field has been dominated by what critics call "the bigger is better" mentality, where progress was measured primarily by scaling up model size and training data.
"What DeepSeek has demonstrated is that architectural innovation and computational efficiency can be just as powerful as raw scale," explains Dr. Samantha Wu, an AI philosopher I spoke with after my visit. "This could inspire a whole new wave of innovation focused on doing more with less—which is ultimately the definition of true technological progress."
The black boxes humming in that climate-controlled data center aren't just processing tokens and adjusting weights—they're quietly reshaping our technological future, one optimized computation at a time.